列存储格式ORC与Parquet详解及其在数据处理和存储服务中的应用比较
引言:列存储时代的崛起
随着大数据技术的飞速发展,传统行式存储(如CSV、JSON)在处理海量数据分析任务时,逐渐暴露出I/O效率低、压缩比差、查询性能瓶颈等问题。在此背景下,列式存储格式应运而生,通过将同一列的数据连续存储,极大地优化了读取性能、压缩效率和查询速度。Apache ORC(Optimized Row Columnar)和Apache Parquet作为当今最主流的两种列式存储格式,已成为构建现代数据湖、数据仓库及数据处理管道的事实标准。本文将对ORC和Parquet进行深入解析,并从数据处理和存储支持服务的角度,系统比较两者的特性与适用场景。
核心特性解析:ORC与Parquet的技术架构
1. Apache ORC
ORC最初由Hortonworks为优化Hive性能而设计,现已发展为Apache顶级项目。其核心设计思想是“为读写Hive数据而优化”。
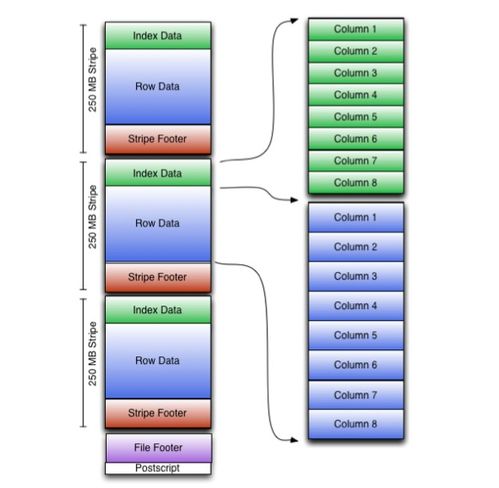
- 文件结构:ORC文件由 stripes(条带)、file footer(文件尾部)和 postscript(后记)组成。每个stripe通常包含多行数据(默认为10,000行),内部又细分为Index Data、Row Data和Stripe Footer,其中索引数据支持实现高效的谓词下推和跳过无关数据块。
- 类型系统:紧密集成Hive数据类型,对复杂类型(如struct、list、map)支持良好。
- 编码与压缩:采用多种轻量级编码(如Run-Length Encoding、Dictionary Encoding)结合zlib、Snappy、ZSTD等压缩算法,通常能达到极高的压缩比。
- ACID支持:ORC原生支持Hive事务(ACID),允许在表级别进行更新、删除和合并操作,这对于需要处理缓慢变化维度或实时更新的场景至关重要。
- 谓词下推:通过内置的布隆过滤器和索引,可在读取时高效过滤数据,减少I/O。
2. Apache Parquet
Parquet由Twitter和Cloudera联合创建,灵感来自Google的Dremel论文,强调跨生态系统的兼容性和高性能。
- 文件结构:采用分层结构,由Row Group、Column Chunk和Page构成。Row Group是数据水平分割的逻辑单元,Column Chunk代表一个列在Row Group内的数据,Page是压缩和编码的最小单位。这种结构便于并行处理。
- 类型系统:基于Dremel的嵌套数据模型,对嵌套数据结构(如JSON、Protocol Buffers、Avro)的支持尤为出色,无需扁平化即可高效存储。
- 编码与压缩:支持灵活的编码方式(如Dictionary、Plain、Delta Encoding),并常用Snappy、GZIP压缩,在保持良好压缩比的注重读写速度的平衡。
- 架构无关性:设计目标是与数据处理框架(如Spark、Presto、Impala)和查询引擎解耦,拥有广泛的语言绑定和生态系统支持。
- 丰富的元数据:在文件尾部存储详细的统计信息(如最小值、最大值、空值计数),优化查询计划。
数据处理与存储支持服务角度的深度比较
| 比较维度 | ORC | Parquet | 对数据处理与存储服务的启示 |
|----------------------|----------------------------------------------|----------------------------------------------|------------------------------------------------------------|
| 生态系统与集成 | 深度集成Hadoop/Hive生态,是Hive默认存储格式。与Spark、Presto等集成良好,但在非Hive场景下,工具链相对专一。 | 生态系统极为广泛,是Spark默认推荐格式,与Impala、Presto、Arrow、AWS Athena/Glue等云服务深度集成,跨平台性极佳。 | Parquet在构建多引擎、多云环境的现代数据平台时更具灵活性。ORC在传统Hive数仓中仍是可靠选择。 |
| 读写性能 | 写性能通常更优,因其结构针对Hive MR作业优化。读性能在基于Hive的查询中表现卓越,特别是全表扫描和聚合查询。 | 读性能在多数分析型查询中领先,尤其是涉及嵌套列和选择性投影时。Spark等引擎对其优化极深。写开销可能略高于ORC。 | ETL管道写入密集型且基于Hive:考虑ORC。交互式分析、多维度查询为主:Parquet往往更快。 |
| 存储效率与压缩 | 通常能达到更高的压缩比(尤其在文本数据上),节省存储成本。 | 压缩比优秀,与ORC互有胜负,更侧重于平衡压缩率与解压速度。 | 对存储成本极度敏感(如冷数据归档),ORC可能有优势。对需要快速扫描的热数据,Parquet的平衡性更佳。 |
| 模式演进与兼容性 | 支持模式演进(如添加列),但ACID事务的支持使其在更新场景更独特。 | 对模式演进的支持非常成熟和优雅,被广泛用于数据湖场景,适应数据模式随时间变化的常态。 | 数据湖架构、模式变化频繁:Parquet是首选。需要行级更新的事务表:ORC的ACID支持不可替代。 |
| 嵌套数据支持 | 支持,但设计和优化更多围绕Hive的SQL-on-Hadoop场景。 | 原生为嵌套数据设计,存储和查询效率更高,是处理半结构化数据(如JSON)的理想选择。 | 数据源多为JSON、Avro或具有复杂嵌套结构:强烈推荐Parquet。 |
| 云原生与对象存储 | 兼容主流对象存储(S3、ADLS、GCS),但文件不可分割性在某些场景下可能影响性能。 | 同样兼容良好,且由于其元数据结构和广泛优化,在云上交互式查询服务(如Athena、BigQuery)中通常是第一公民。 | 云上数据湖建设,Parquet的社区支持和云厂商优化通常更全面。 |
与选型建议
ORC和Parquet都是卓越的列式存储格式,没有绝对的优劣,只有更适合的场景。
- 选择Apache ORC,当您的场景是:
- 以Hive为中心的传统数据仓库,且工作负载大量涉及Hive SQL。
- 对存储空间压缩比有极致要求,存储成本是首要考量。
- 业务需要Hive表级别的ACID事务支持,进行频繁的行级更新、删除。
- 选择Apache Parquet,当您的场景是:
- 构建以Spark、Presto、Impala等现代引擎为核心的数据湖或数据平台。
- 数据源或模型包含大量嵌套、半结构化数据。
- 追求最广泛的生态系统兼容性,需要无缝对接多种计算引擎和云服务。
- 业务以复杂的交互式分析查询为主,且模式可能随时间演进。
未来趋势与融合:随着数据处理服务的发展(如Delta Lake、Apache Iceberg、Hudi等表格式的兴起),ORC和Parquet更多作为底层物理存储格式被封装。这些高级表格式在提供ACID、时间旅行等功能的让用户无需在ORC和Parquet之间做出艰难抉择,有时甚至支持两者作为底层文件格式。因此,在架构选型时,也应将上层表格式的生态支持纳入考量。
一个混合并存的环境也可能是合理的——在同一个数据平台中,根据数据的特点、访问模式和生命周期管理策略,为不同的数据集选择最合适的存储格式,方能最大化数据处理与存储服务的效能与成本效益。
如若转载,请注明出处:http://www.xnjindouyun.com/product/67.html
更新时间:2026-04-20 20:04:30