分布式大数据高并发Web开发框架 数据处理与存储支持服务架构解析
在当今数字化浪潮中,面对海量数据和高并发请求的挑战,传统的单体Web框架已难以满足需求。分布式大数据高并发的Web开发框架应运而生,其核心在于构建一套高效、可扩展的数据处理与存储支持服务体系。本文将深入探讨此类框架的关键组件、架构设计及实现原理。
一、框架核心架构概述
分布式大数据高并发Web框架通常采用微服务架构,将系统拆分为多个独立部署的服务单元。数据处理与存储支持服务作为框架的基石,主要包括数据采集、实时计算、批量处理、分布式存储和缓存等模块。这些模块通过消息队列、服务网关和配置中心协同工作,确保系统的高可用性和弹性扩展。
二、数据处理服务的关键技术
- 流式数据处理:采用Apache Kafka、Apache Pulsar等消息队列实现数据的高吞吐量传输,结合Apache Flink或Apache Storm进行实时流计算,支持事件时间处理、状态管理和Exactly-Once语义。
- 批处理引擎:集成Apache Spark或Hadoop MapReduce,通过内存计算和DAG执行引擎优化大规模数据集的离线分析任务。
- 数据湖与数据仓库:支持将原始数据存储在Delta Lake、Iceberg等数据湖格式中,并通过Apache Hive、Presto等查询引擎实现交互式分析。
三、分布式存储支持服务
- 多模数据库集成:
- 关系型数据库:通过ShardingSphere等中间件实现MySQL/PostgreSQL的分布式分片。
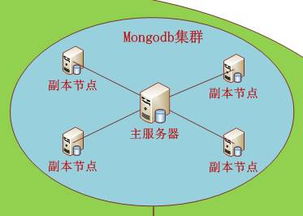
- NoSQL数据库:集成Cassandra(宽列存储)、MongoDB(文档型)、Redis(缓存)等,满足不同场景的数据模型需求。
- 时序数据库:选用InfluxDB或TimescaleDB处理物联网、监控指标等时序数据。
- 对象存储服务:兼容Amazon S3协议的MinIO或Ceph,用于存储图片、视频等非结构化数据。
- 分布式文件系统:基于HDFS或CephFS构建PB级存储集群,提供高可靠的文件存取服务。
四、高并发优化策略
- 异步非阻塞架构:采用Netty、Vert.x等框架实现I/O多路复用,配合Reactive编程模型提升单节点并发处理能力。
- 多级缓存体系:
- L1缓存:使用Caffeine实现本地堆内缓存。
- L2缓存:通过Redis Cluster构建分布式缓存层。
- 缓存一致性:采用Cache-Aside模式结合消息总线实现数据同步。
- 连接池优化:定制化开发数据库连接池,支持动态扩容和慢查询熔断。
五、运维与监控支持
- 可观测性体系:集成Prometheus收集指标数据,通过Grafana可视化展示;使用Jaeger或SkyWalking实现分布式链路追踪。
- 自动化运维:基于Kubernetes的Operator模式实现数据库集群的自愈和弹性伸缩。
- 数据治理:通过Apache Atlas构建数据血缘关系,配合数据质量检测工具确保数据处理流程的可靠性。
六、典型应用场景
- 电商秒杀系统:通过分布式缓存抗住瞬时流量,使用流计算实时更新库存。
- 物联网平台:用时序数据库存储设备数据,通过Flink进行异常检测。
- 金融风控系统:结合图数据库与流计算实现实时反欺诈分析。
构建分布式大数据高并发Web框架的数据处理与存储服务体系,需要综合考虑数据一致性、系统吞吐量和运维复杂度之间的平衡。未来随着云原生技术和AI芯片的发展,存算分离架构与智能调度算法将进一步推动该领域的革新。开发者应当根据业务特征选择合适的技术组合,而非盲目追求新技术,方能在数据洪流中构建坚实的技术方舟。
如若转载,请注明出处:http://www.xnjindouyun.com/product/61.html
更新时间:2026-04-20 03:38:23