大型分布式网站架构技术总结 数据处理与存储支持服务
在当今互联网高速发展的背景下,大型分布式网站已成为支撑海量用户访问和数据业务的核心基础设施。数据处理与存储支持服务作为分布式架构的关键组成部分,直接影响系统的性能、可靠性和扩展性。本文将从数据分片、存储引擎、缓存策略、数据备份与恢复以及数据一致性等角度,系统总结大型分布式网站中数据处理与存储支持服务的关键技术。
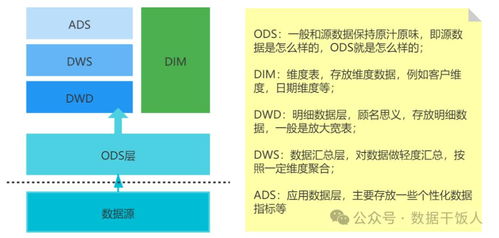
一、数据分片技术
数据分片(Sharding)是解决海量数据存储和访问性能问题的常用手段。通过将数据按特定规则(如哈希、范围或列表)分布到多个数据库节点,实现水平扩展。常见的分片策略包括:
1. 水平分片:按行拆分数据,适用于表数据量巨大的场景。
2. 垂直分片:按列拆分数据,适合表中字段多且访问模式差异大的情况。
分片技术需考虑数据均匀分布、跨片查询优化以及动态扩容等问题。
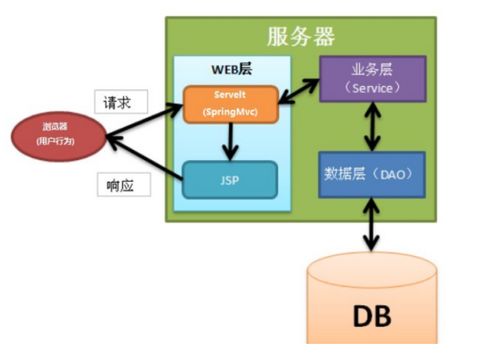
二、分布式存储引擎
分布式存储引擎负责数据的持久化与高效访问。主流技术包括:
1. 分布式关系数据库:如Google Spanner、TiDB,支持ACID事务和SQL接口,适用于强一致性要求的业务。
2. NoSQL数据库:如Cassandra、HBase,适合高吞吐、弱一致性的场景,通过最终一致性模型提升可用性。
3. 对象存储服务:如AWS S3、阿里云OSS,适用于非结构化数据的大规模存储。
存储引擎的选择需结合数据模型、一致性需求及成本因素。
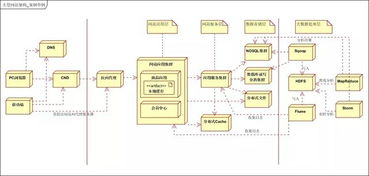
三、缓存策略
缓存是提升数据访问性能的关键技术,通过将热点数据存储在内存中减少数据库压力。常用方案包括:
- 多级缓存:结合本地缓存(如Guava Cache)与分布式缓存(如Redis、Memcached),平衡延迟与一致性。
- 缓存更新策略:采用写穿透(Write-Through)、写回(Write-Back)或失效(Cache-Aside)机制,确保数据新鲜度。
- 缓存预热与淘汰:通过LRU、LFU等算法管理内存资源,避免缓存击穿和雪崩。
四、数据备份与恢复
为保证数据安全,分布式系统需具备完善的备份与恢复机制:
- 多副本存储:通过跨机房、跨地域的数据冗余,提升容灾能力。
- 增量备份与快照:定期备份增量数据,结合快照技术实现快速恢复。
- 一致性备份:利用分布式事务或日志同步(如WAL)确保备份数据的一致性。
五、数据一致性保障
在分布式环境中,数据一致性是核心挑战。常用解决方案包括:
- 强一致性协议:如Paxos、Raft,通过多数派共识保证数据一致性,但可能牺牲部分性能。
- 最终一致性模型:通过冲突解决机制(如向量时钟、CRDT)在可用性与一致性间取得平衡。
- 分布式事务:基于二阶段提交(2PC)或TCC模式,支持跨服务数据操作。
大型分布式网站的数据处理与存储支持服务需综合运用分片、缓存、备份及一致性技术,构建高可用、高性能的数据架构。随着云原生与AI技术的演进,智能调度、自动化运维及混合存储模式将进一步推动分布式数据服务的创新与发展。
如若转载,请注明出处:http://www.xnjindouyun.com/product/36.html
更新时间:2026-04-20 21:02:57